noindexタグとは、Googleのような検索エンジンにページをインデックスさせないようにするためのメタタグのことです。
似たものにnofollowやrobots.txtがあります。
いずれもSEO内部対策として設定されるもので、場合に応じて使い分ける必要があります。
本記事では、「noindexタグとは」「noindexタグの設定方法」などを解説しますので、これからSEO対策を検討されている方は、ぜひ参考にしてみてください。
目次

noindexタグとは
noindexタグとは、Googleのような検索エンジンにページをインデックスさせないようにするためのメタタグのことです。
メディアを作る中で、同一のドメインであらゆるページが生成されます。
そうして生成されたページの中に、SEO的に相応しくないページがあると、メディア全体のSEO評価が下がりかねません。
不要なページをインデックスさせないことで、検索エンジンに必要なページだけを認識させ、正しいSEO評価を得ることが期待できます。
インデックスとは
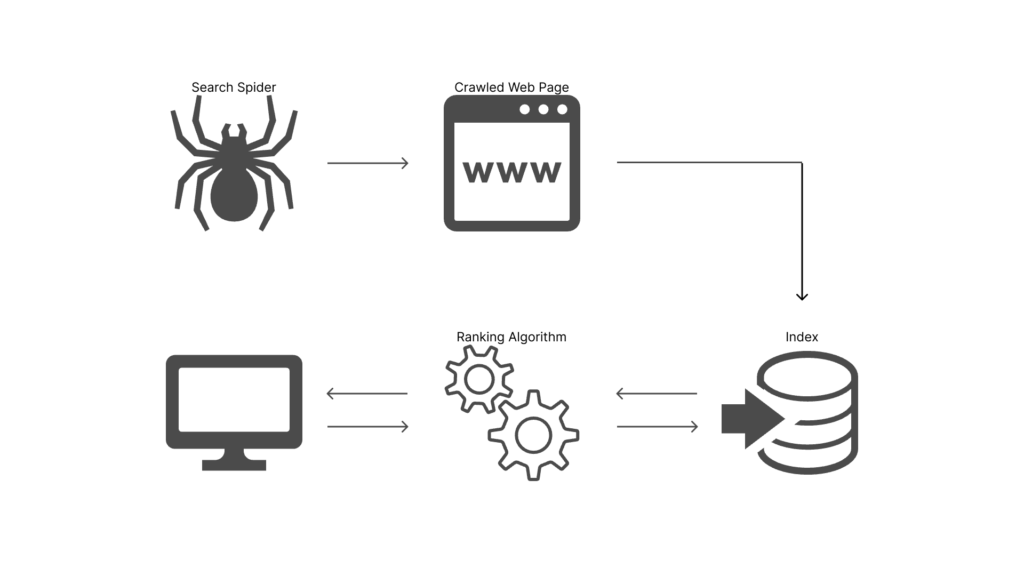
インデックスとは、Webページが検索エンジンのデータベースに格納されることを意味します。
上図は、検索エンジンが検索順位を決めるまでの流れを図にしたものです。
大まかな流れは、以下の3段階で理解できます。
- クロール
- インデックス
- アルゴリズムによる順位決定
noindexタグでは、このインデックスにおいて、それを「させない」よう、メディア運営者側から検索エンジンに伝えることができます。
nofollowとの違い
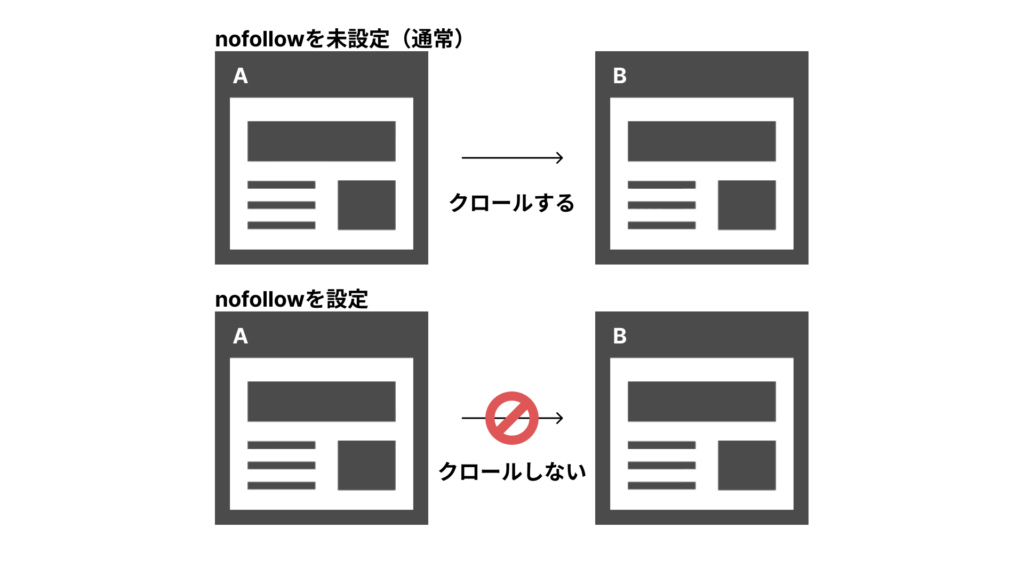
noindexタグと似たものに、nofollowが挙げられることがあります。
noindexは「インデックスをさせない」タグですが、nofollowも同様に「フォローをさせない」タグです。
nofollowが使われる場面は、自サイトから外部サイトへのリンクを貼っている場合です。
自サイトがSEO評価をされる際には、その自サイトからどのような外部リンクを貼っているのか、その関連性なども評価されます。
広告を貼り付けていたり、ページのコメント欄を解放している場合、自サイトに関連性の低い外部リンクが貼られる可能性があります。
そのような自サイトから外部サイトにリンクをした際に、そのリンク先のサイトへのクロールを許すことによって、自サイトに不利益がある場合には、このnofollowを設定します。
nofollowについては、以下の記事で解説しているので、併せてご覧ください。
robots.txtとの違い
- noindexタグ:インデックスをさせない(クロールはされる)
- robots.txt:クロールを制御
robots.txtも、noindexタグと似たものとして扱われることがあります。
noindexタグは、クロール自体はブロックしないのでページ内容を検索エンジンが認識することができます。
robots.txtは、クロールを制御するものです。
この両者を併用すると、「robots.txtでクロールを制御してしまったがために、noindexタグが読み込まれない」などの問題が生じるので、正しく使い分けましょう。
noindexタグのSEO効果
noindexタグは、不要なページを検索エンジンに認識させないという点で、SEO評価を下げないための施策になり、SEO効果があります。
しかしもちろんですが、SEO効果を高めるためには、前提として低品質なページを生成しない工夫を行い、高品質なページを提供することが肝心です。
noindexタグを使う必要があるケース
- コンテンツの質が低いページ
- 重複コンテンツがあるページ
- エラーページ
- HTMLサイトマップページ
コンテンツの質が低いページ
「コンテンツの質が低い」というのは、ブログ記事において有益さに欠ける内容を掲載している、といった意味だけではありません。
例えば、ECサイトもSEO効果を期待することがあります。
商品一覧ページに掲載されている商品数が少なく、ページの情報量が少ない場合は、そのページの品質が低いと見なされます。
このような場合には、noindexタグを指定します。
重複コンテンツがあるページ
重複コンテンツがあると、検索エンジンからの評価がそれぞれに分散することがあり、結果的にどちらもページの掲載順位が上がらない場合があります。
例えば、ECサイトで同一商品の色違いで異なるURLを指定していることがあります。
この場合、色の情報以外が重複した内容となるため、検索エンジンから重複コンテンツとして見なされます。
重複コンテンツがある場合には、検索エンジンに認識されたい1つだけを残し、他にはnoindexを指定して解決する方法があります。
しかし、このケースではURL正規化という手段を取ることが一般的です。
重複したコンテンツを掲載している複数のURLの中から、「正規の」URLを指定し、SEO効果をその1つのURLに移すという方法です。
URL正規化やcanonicalタグについては、以下の記事をご覧ください。


エラーページ
エラーページは、404エラーページのようなものを指します。
そのサイト内にページが存在しないことを示すエラーページなどは、検索結果に掲載する必要がないため、noindexタグを指定します。
しかし、設定をしなくても、SEO的に悪影響を及ぼすことはないため、設定は必須ではありません。
404エラーページについては、以下の記事で設定方法などを解説しているので、詳しくはこちらをご覧ください。
HTMLサイトマップページ
HTMLサイトマップとは、ユーザー向けに作成された、そのサイトのページのリンクの一覧ページのことを言います。
こちらも検索結果に掲載する必要がないページであるので、noindexタグを指定します。
サイトマップはSEO対策において、クロールを促す際などに活用されます。
サイトマップについて知りたい方は、下記のリンクからご覧いただけます。

noindexタグの設定方法
noindexタグを設定する方法を解説します。
HTMLファイルに直接設定する方法
noindexタグを設定するには、適用したいページのHTMLファイルのheadタグ内に、以下の内容を記述します。
<head>
<meta name=”robots” content=”noindex”/>
</head>クローラーを指定してブロックすることも可能です。
※Googleのクローラーをブロックする場合
<meta name=”googlebot” content=”noindex”/>以上の記述で、そのページの「noindexタグ」の設定が完了です。
HTMLファイル以外にnoindexタグを設定する方法
PDFや画像ファイルなど、HTMLファイル以外でもHTTPレスポンスヘッダーに記述することでnoindexを設定することができます。
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)WordPressで設定する方法
WordPressでnoindexタグを設定する際には、プラグインを利用することが一般的です。
このSEO内部対策を行うプラグインの中でも、最もメジャーなのは、「All in One SEO」です。
こちらのプラグインを入れることで、直接ファイルを編集することなく、ページの編集画面からnoindexタグを設定することができます。
noindexタグの設定の確認方法
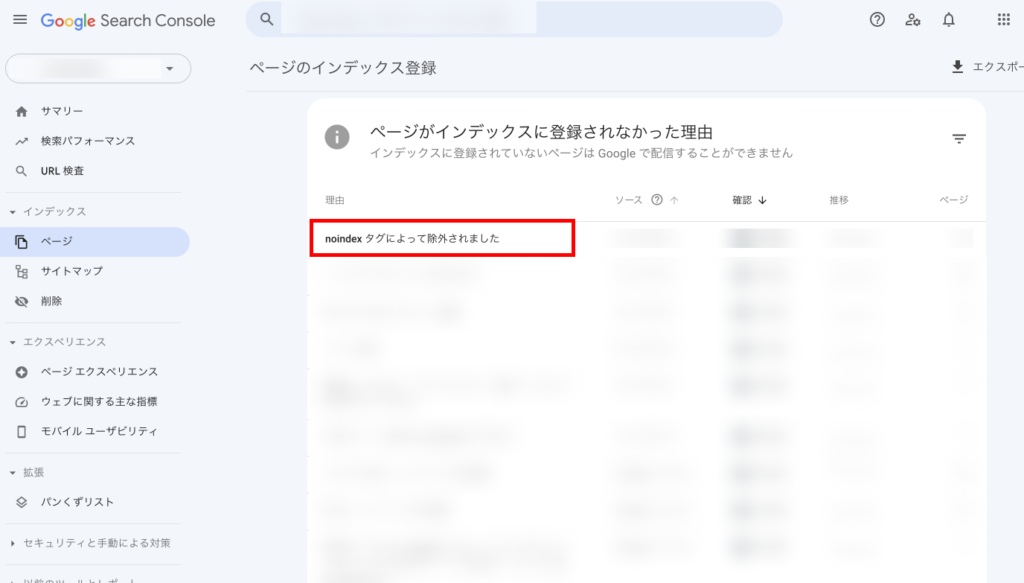
実際にnoindexタグを指定した後には、それが機能しているかを確認します。
Google Search Consoleを使うことで、noindexタグによってインデックスから除外されているかを確認することができます。
「インデックス」→「ページ」から「ページがインデックスに登録されなかった理由」を確認します。
その中に、「noindex タグによって除外されました」の項目があるので、それをクリックすることで、具体的にどのページが除外されたのかを確認することができます。
noindexタグを設定してから、反映されるまでに時間がかかる場合があります。
noindexタグを設定する前に、URL正規化・ページ削除の検討は必要
noindexタグの設定を検討するケースの中には、「ページ内容が重複している」「不要なページがある」ことを解決したい場合もあるかと思います。
そのような場合は、まずはページの削除を検討することをお勧めします。
または、重複しているだけであるなら、URL正規化、特にcanonicalタグの設定で解決することがほとんどです。
当サイトでは、他にもSEO内部対策に関する記事を更新しているので、ぜひ併せてご覧ください。