構造化データとは、「行」と「列」の概念を持つ、構造化されたデータのことを指します。
それに対して、非構造化データとは、こういった「構造」を持たないデータのことを指します。
- 構造化データの例:Excel、CSVなど
- 非構造化データの例:テキスト、Eメール、画像など
この「構造化データ」について気になっている方の中には、Googleの検索エンジンに最適化する際における「構造化データ」の意味に関心がある方が多いかと思います。
この記事では、そういった「SEOにおける構造化データの意味」「マークアップ方法」などについて解説します。
構造化データのマークアップは、SEO内部対策の中の1つです。
他の施策についてご興味のある方は、SEO内部対策の記事もご覧になってみてください。
目次

構造化データとは|非構造化データとの違い
構造化データとは、「行」と「列」の概念を持つ、構造化されたデータのことを指します。
非構造化データとは、こういった「構造」を持たないデータのことを指します。
非構造化データは、日常的に生成されることが多いことは想像に易いですが、構造を持たない故に扱いが難しい特徴があります。
WEBページなどのHTMLデータは、一定の規則性を持つデータではありますが、構造化データとしては見なされていません。
Googleに対してそのWEBページの情報を伝えるには、Googleにとってわかりやすい形で、こちらから「構造化データ」に加工し、伝える必要があるということです。
セマンティックWebとは
セマンティックWebとは、Webページに記述された内容について、それが何を意味するかを表す「情報についての情報」(メタデータ)を一定の規則に従って付加し、コンピュータシステムによる自律的な情報の収集や加工を可能にする構想。
セマンティックWeb 【Semantic Web】-IT用語辞典 e-Words
この構造化データをもとに検索エンジンが情報を処理することは、セマンティックWebという発想に基づいています。
HTML形式のWEBページをテキストとして読み込むだけではそれ以上の解釈をすることができないため、その情報に対して更に情報を付加し、「意味」のある情報として蓄積しようとする考え方です。
構造化データのマークアップ方法
実際に、構造化データをマークアップするにあたって、まずはGoogle公式が発表している、構造化データに関する一般的なガイドラインを理解することが必要です。
マークアップをしているようでも、このガイドラインに準拠していなければ、リッチリザルトとして表示されるなどのメリットを受けることができません。
ボキャブラリーとシンタックス
さて、その方法を解説するために、まずは「ボキャブラリー」と「シンタックス」について説明します。
ボキャブラリーとは、構造化データをマークアップする際の値を定義する規格を指します。
人名なら"name”という値を、所要時間なら"totaltime"といった定義をするものです。
そのボキャブラリーの1つにSchema.orgがあり、Googleはこれに準拠しています。
シンタックスとは、構造化データをマークアップする際の仕様を指します。
- JSON-LD(これが推奨されている)
- RDFa
- Microdata
この記事では、Schema.orgに基づき、JSON-LDの仕様でマークアップする方法を解説します。
HTMLファイルに直接マークアップする
HTMLファイルに直接マークアップする際には、まずはその対象となるHTMLファイルを開き、headタグ内に書いていきます。
【ブログ記事の構造化データマークアップ例】
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BlogPosting",
"headline":"構造化データとは|マークアップ方法やそのメリットを解説",
"image": {
"@type": "ImageObject",
"url": "https://growweb.jp/wp-content/uploads/2022/10/構造化データとは-マークアップ方法やそのメリットを解説.png",
"height": 250,
"width": 785 },
"datePublished": "2022-10-01",
"dateModified": "2022-10-01",
"author": {
"@type": "Person",
"name": "GROWWEB"
},
"publisher": {
"@type": "Organization",
"name": GROWWEB"
},
"description": "構造化データとは、「行」と「列」の概念を持つ、構造化されたデータのことを指します。それに対して、非構造化データとは、こういった「構造」を持たないデータのことを指します。
"
}
</script>このページを構造化データマークアップをする場合の例は、以上のようなものになります。
それぞれのプロパティは、Schema.orgによって定義されていますが、実際にどのような情報を記載するかは、マークアップの仕方によります。
コンテンツの形式によって、どのようなプロパティに対して値を入れるかを判断する必要があるので、マークアップの前に、「構造化マークアップによって、どのようなリッチリザルトが表示されることを期待するか」を考え、それを実現するために必要なプロパティの選び方をする必要があります。
WordPressの場合は、動的になるように置き換える
WordPressで構築したサイトに、この構造化データのマークアップを実施する場合は、動的に変化する箇所をWordPressの記述に置き換える必要があります。
ページのタイトルやURLなど、そのページによって内容が変化する場合、手作業でそれぞれを書き換えることは困難であるので、予めその変化に対応できるように記述します。
<?php
$thumbnail_id = get_post_thumbnail_id($post);
$imageobject = wp_get_attachment_image_src( $thumbnail_id, 'full' );
?>
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BlogPosting",
"headline":"<?php the_title(); ?>",
"image": {
"@type": "ImageObject",
"url": "<?php echo $imageobject[0]; ?>",
""height": <?php echo $imageobject[2]; ?>,
"width": <?php echo $imageobject[1]; ?>
},
"datePublished": "<?php echo get_date_from_gmt(get_post_time('c', true), 'c');?>",
"dateModified": "<?php echo get_date_from_gmt(get_post_modified_time('c', true), 'c');?>",
"author": {
"@type": "Person",
"name": "GROWWEB"
},
"publisher": {
"@type": "Organization",
"name":”<?php bloginfo('name'); ?>”
},
"description": "<?php echo mb_substr(strip_tags($post-> post_content),0,70).'...'; ?>"
}
</script>以上のコードは、ページによって変化する部分をWordPressの関数に置き換えたパターンです。
ページのタイトル、URL、サムネイル、投稿日時・更新日時などを置き換え、どの記事ページでも対応できるようにしています。
WordPressで使われる関数については、日本語版のリファレンスがあるので、そちらを参考にしてみてください。
ツールを使用する
ここまで、構造化データのマークアップを自分で行うことを前提に解説しましたが、ツールを用いることでも、構造化データのマークアップはすることができます。
構造化データ マークアップ支援ツール
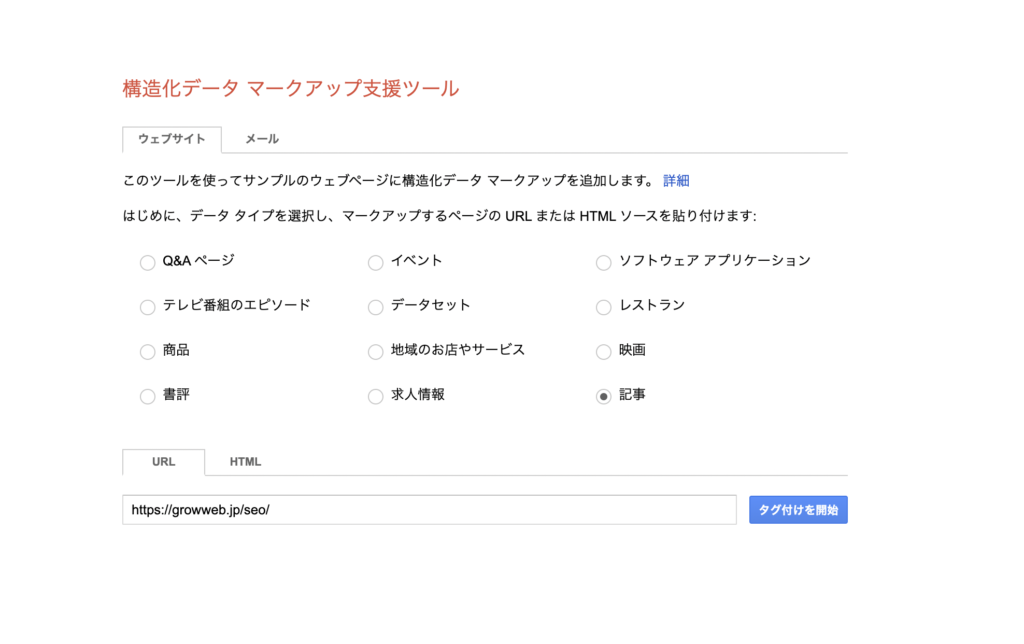
Googleの提供する「構造化データマークアップ支援ツール」では、コードを自分で書くことなく、実装することができます。
記事ページの構造化データをマークアップする場合は、「記事」を選択し、「URL」に対象となるページのURLを記入します。
「タグ付けを開始」を押すと、以下のように画面が切り替わります。
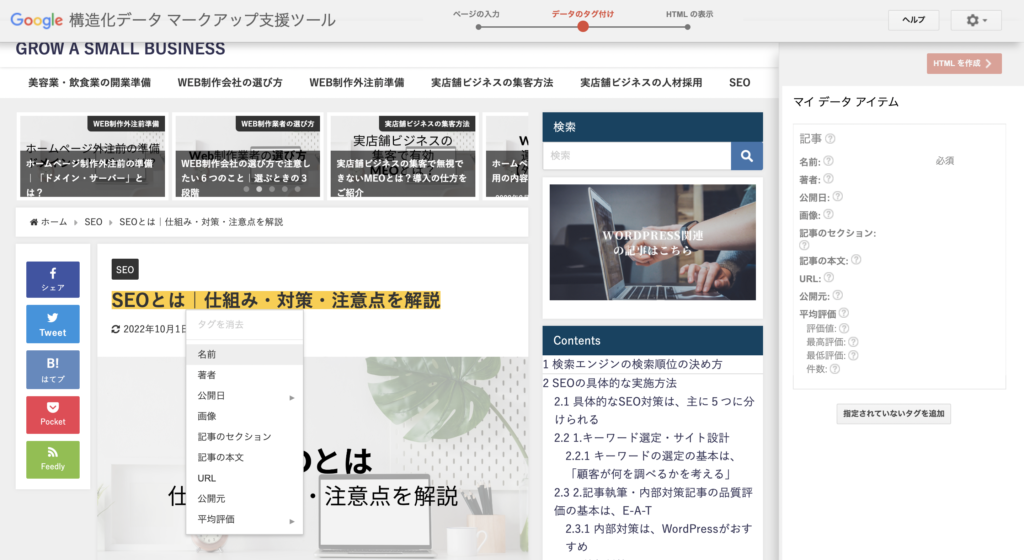
マークアップしたい箇所をドラッグし、それぞれに対してタグ付けをしていきます。
タグ付けを一通り終えると、「HTMLを作成」に進みます。

すると、上図のように、JSON-LD形式でマークアップされた構造化データが出力されます。
このようにツールを使うと、簡単にマークアップすることは可能ですが、それぞれのタグの意味や、どのタグを使うべきかなどの判断は自分でする必要があります。
そのため、ツールはあくまでもマークアップする上での補助であり、自分でマークアップができる状態に理解を深める必要があります。
構造化データのテスト方法
ここまでの方法で構造化データのマークアップが完了した後に、その内容が有効であるかを確認する必要があります。
構造化データのテストツールを使って検証します。
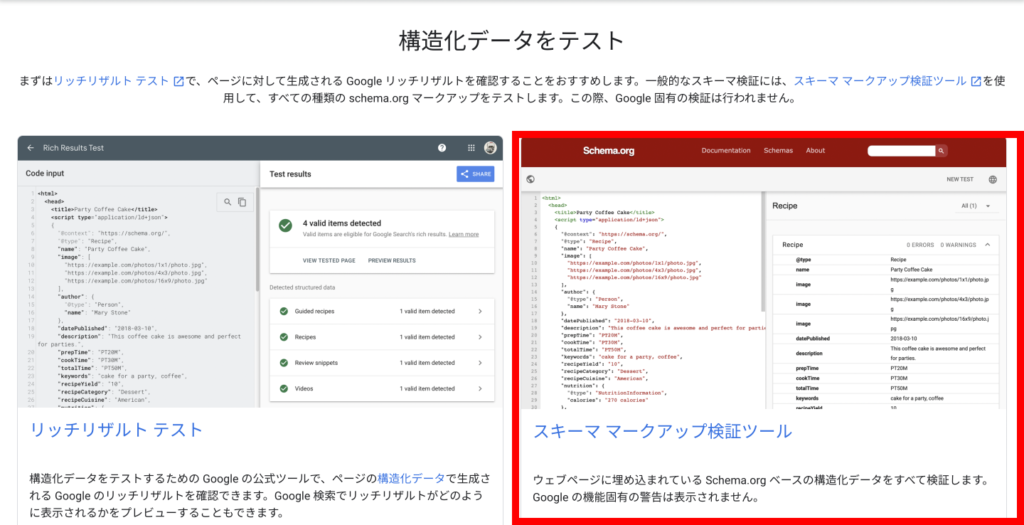
ページにアクセスすると、以上のようなページが表示されるので、今回は右側の「スキーマ マークアップ検証ツール」を使用します。
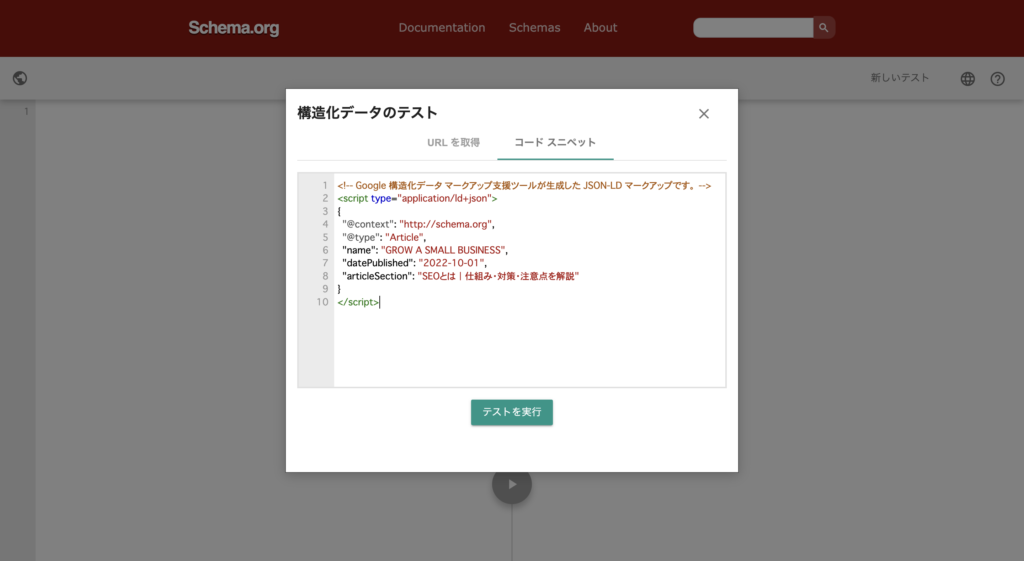
クリックすると、以上のようなウィンドウが表示されるので、「コードスニペット」を選択し、検証したいコードを記入します。
既に公開されているページに対して検証したい場合は、「URLを取得」を選択し、URLから検証を開始します。
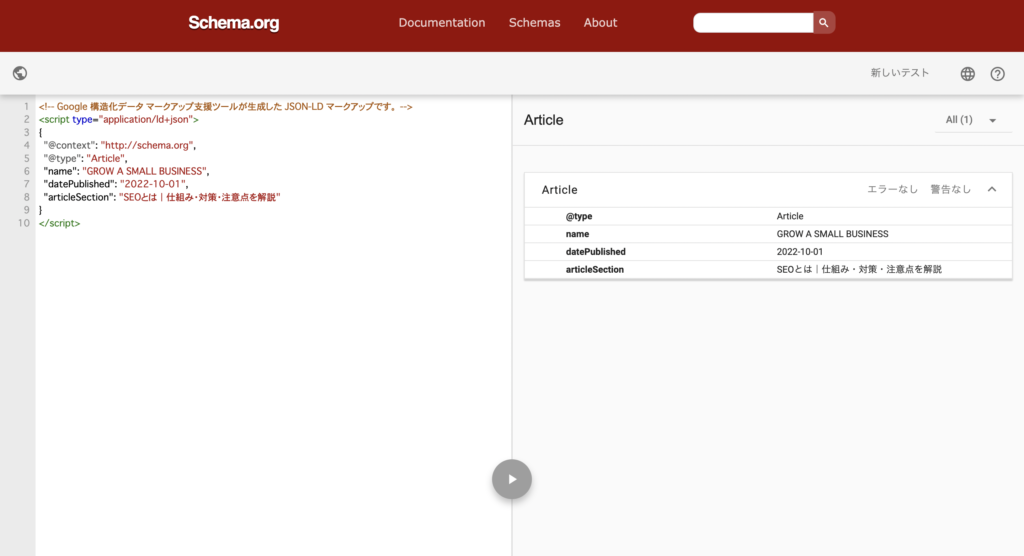
「テストを実行」をクリックすると以上のような画面になります。
エラーがあるとエラー内容が表示されるので、記述に誤りがないか、必要な情報が記入されているかなどを確認しましょう。
構造化データのマークアップのメリット
- 検索エンジンがページ内容を理解しやすくなる
- リッチスニペット(リッチリザルト)が表示されることがある
構造化データのマークアップは、SEO内部対策の1つです。
そのメリットは主に2つのことが挙げられます。
検索エンジンがページ内容を理解しやすくなる
構造化データのマークアップによって、そのページの内容をより正しく検索エンジンに伝えることができます。
しかし、直接的なSEO効果はありません。
タグをつけ、情報に意味を持たせ、伝えることで、クローラビリティが上がり、間接的にSEOに寄与する場合があります。
リッチスニペット(リッチリザルト)が表示されることがある

リッチスニペット(リッチリザルト)は、検索結果のページのタイトルの周辺に表示される、ユーザーの理解の助けとなるページの情報のことを指します。
上図は、リッチスニペットの例であり、「パンくずリスト」や「ディスクリプション」が表示されていることがわかります。
リッチスニペットには他にも、以下のような種類があります。
- パンくずリスト
- 商品情報
- サイトリンク
- 店舗情報
- スケジュール
- 求人情報
- よくある質問
- 写真・動画
- 検索窓
など。
リッチスニペットの表示のされ方で、そのサイトに対するユーザーからの見られ方や、クリック率に影響を及ぼす可能性があります。
これらを有効に活用するには、構造化データのマークアップは必要であると言えます。
構造化データのマークアップのデメリット
- 専門知識が必要
- 手間がかかる
一方で、構造化データのマークアップにはデメリットがあります。
専門知識が必要
本記事で説明したように、構造化データのマークアップには多少の専門知識が必要になります。
記述方法を理解し、ボキャブラリーを参照し、適切に値を入れていく作業は、他のSEO内部対策に比べると、よりエンジニアが対応する領域に近いと言えます。
場合によっては、コードを編集する担当者にお願いする必要があるかもしれません。
手間がかかる
手間がかかることも、構造化データのマークアップのデメリットであると言えます。
記述方法に則って、マークアップをしても、その内容が有効であるかを検証する必要があります。
検証し、エラーが出ない状態にしていくまでに多少なりの手間がかかります。
初めてマークアップをする方が、どれほどの手間がかかるかの予測が立てづらいことはデメリットであると言えます。
構造化データのマークアップをして、リッチスニペットを表示させよう
構造化データのマークアップは、それ自体にSEO効果はありませんが、クローラビリティ・ユーザビリティの向上が期待されることから、間接的にSEO効果があるとされています。
昨今のSEO対策においては、必須とされつつあるので、構造化データのマークアップをまだしていない方は、ぜひこの記事を参考に、実施してみてください。
当サイトでは、他にもSEO内部対策についてご紹介しているので、ぜひご覧ください。